
Endpoints
(These endpoints won’t be public accessible in a production environment execept the demo site)
- Demo Site
- Github
- Eureka Dashboard
- Springdoc OpenAPI
- Prometheus
- Grafana
- Kibana
Content Outline
- Architecture Overview
- Introduction to Each Microservice
- Product Caching
- Overall Caching Process
- Cache Penetration
- Cache Breakdown
- Cache Avalanche
- Searching
- Authentication
- Session-based Token Auth
- Comparison with JWT
- System Optimization
- User ID Penetration
- Asynchronous Orchestration
- Decoupling
- Payment Handling
- Deployment
- Local Deployment
- Full Deployment on AWS
- Terraform: Infrastructure as Code
1. Architecture Overview
This project is for learning purposes, it’s based on “Josh tried coding” turtorial, with many extra features and a self-designed/coded backend.
Overall, DigitalHippo is a client-server (C/S) architecture application with a separate frontend and backend.
The frontend application is developed with Nextjs 14, Typescript, TailwindCSS for the styling and Shadcn UI as the component library.
The backend is a Microservice Architecture application, using SpringBoot, SpringCloud (Netflix, AWS, OpenFeign …), with Java 17 and Kotlin 2.0.20
The backend application integrates with ELK Stack (Elasticsearch, Logstash, Kibana) for Central Logging Management. This will help the operation team to observe system activities, trouble shoot problems and investigate the root cause.
The backend application also integrates with Prometheus and Grafana, this will allow operation team to monitor system performance through its metrics.
2. Introduction to Each Microservice
Overview
There are 8 different types of microservices in total:
(The following endpoints in the table won’t be public accessible in production environment)
| Microservice Name | Programming Lanuage | Description | Springdoc API | Kibana Dashboard |
| Eureka | Java | Service registry | / | / |
| Server Gateway | Java | Application gateway | / | Server Gateway |
| User | Kotlin | Handles business operations regarding users and authentication. | Swagger-UI (MS USER) | MS USER |
| Product | Kotlin | Handles all the CUD operations of Products. | Swagger-UI (MS PRODUCT) | MS PRODUCT |
| Search | Java | Handles all the product searching requests using ElasticSearch. | Swagger-UI (MS SEARCH) | MS SEARCH |
| Cart | Kotlin | Handles all the CRUD operations regarding Cart operations. | Swagger-UI (MS CART) | MS CART |
| Kotlin | Integrated with Gmail STMP to send email to users when they first created their accounts or made a purchase. | / | MS EMAIL | |
| Stripe | Java | Integrates with Stripe, and handles all the payment operations. | Swagger-UI (MS STRIPE) | MS STRIPE |
All microservice applications are constructed and managed by Apache Maven
MS Eureka
Eureka Server works as a Client-side service registry. Each microservice will register itself with Eureka. When other microservices need to communicate, they query Eureka to discover the instance of the service they need.
This will allow:
- Dynamic discovery of services as they scale up or down.
- Load balancing across available instances of a service.
- Fault tolerance, as Eureka removes or marks down failed services, allowing others to bypass them.
The Eureka Dashboard can be accessed here.
(This endpoint won’t be public accessible in production environment)
MS Server Gateway
Spring Cloud Gateway acts as an API entry point for all client requests. It distributes the incoming requests to the appropriate microservices and handles the authentication, logging, and rate limiting. In this project, The Server Gateway microservice uses Global Filters for Authentication and User ID Penetration.
MS Cart
The Cart microservice is programmed in Kotlin, It handles all CRUD operations related to cart management, including:
- Persisting cart items when the user adds products
- Combining the user’s cart items if they added products before logging in
- Removing cart items once the user creates an order
MS Email
The Email microservice is programmed in Kotlin, it implements two AWS SQS listener to receive the data for constructing Account Verification Email or Receipt Email based on pre-configured HTML templates. Then it will send the email using JavaMailSender via Gmail STMP. Source code for this feature.
3. Product Caching
Overall Caching Process
1. Query Without Cache

In this scenario, PostgreSQL will receive all the workload directly from clients, causing several issues:
- Slow response times: Accessing a cache is typically much faster than querying a relational database. Without a caching mechanism, every client request will trigger a database access rather than a cache query.
- High database load: Frequent access will increase the database workload, potentially causing performance drops or even crashes.
- Poor scalability: As the Product Service scales up to handle high volumes, PostgreSQL can easily become a bottleneck since all client requests result in database access.
2. Caching with Redis
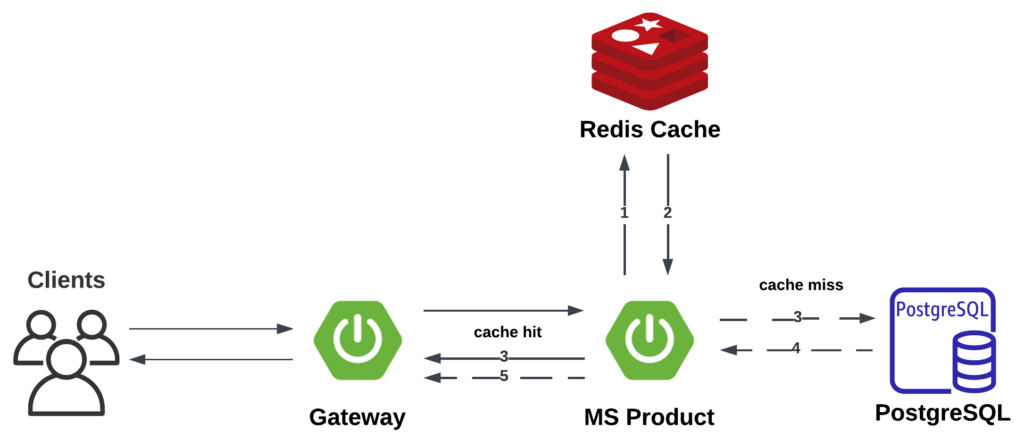
To address the above issues, a caching mechanism is required.
We can use Redis as a caching server, which only interacts with RAM if we turn off RDB and AOF (RDB and AOF is not needed because we are using redis for caching). Typically this will be much faster than PostgreSQL considering Postgres will interact with the disk.
With Redis as the caching server, the application will avoid querying PostgreSQL if the product information is already present in the Redis.
3. Caching Strategies
There are two caching strategies:
Cache-Aside (Lazy Loading)
- Only requested data are cached
- Cache miss penalty results in 3 calls (query cache, query db, write to cache)
Write Through
- Read is always quick (cache hit)
- Write penalty: each write requires 2 calls (write to db, write to cache)
In this project, Cache-Aside (Lazy Loading) strategy is implemented. The reason is that for a E-Commerce application, the full dataset of products is too large to put in Cache, using Cache-Aside strategy will alow us to only cache recently requested data.
Up to now, we have successfully solved the above problems by adding caching with Redis. However, we are now facing several new challenges:
- Cache Penetration – How do we protect the database if someone attempts to compromise it by querying a large number of nonexistent products?
- Cache Breakdown – How can we protect the database when a cached product expires, the next moment a large number of requests simultaneously query this specific product’s information?
- Cache Avalanche – How can we prevent the database from being overwhelmed if a large amount of cached data expires simultaneously, right before a large number of requests come in?
Cache Penetration
Cache penetration occurs when someone queries nonexistent data. The cache cannot block these requests because the application doesn’t hold the information of the queried data’s existence.
We can typically address this issue by introducing a mechanism to determine a data’s existence. Two algorithms are commonly used for this purpose:
Bloom Filter
Bloom filter is a probabilistic data structure that tests whether an element is in a set, with a chance of false positives but no false negatives, saving memory for large datasets.
Bitmap
Bitmap is a memory-efficient data structure using bits to represent the presence or absence of elements within a fixed range.
I used Bitmap to solve this issue.
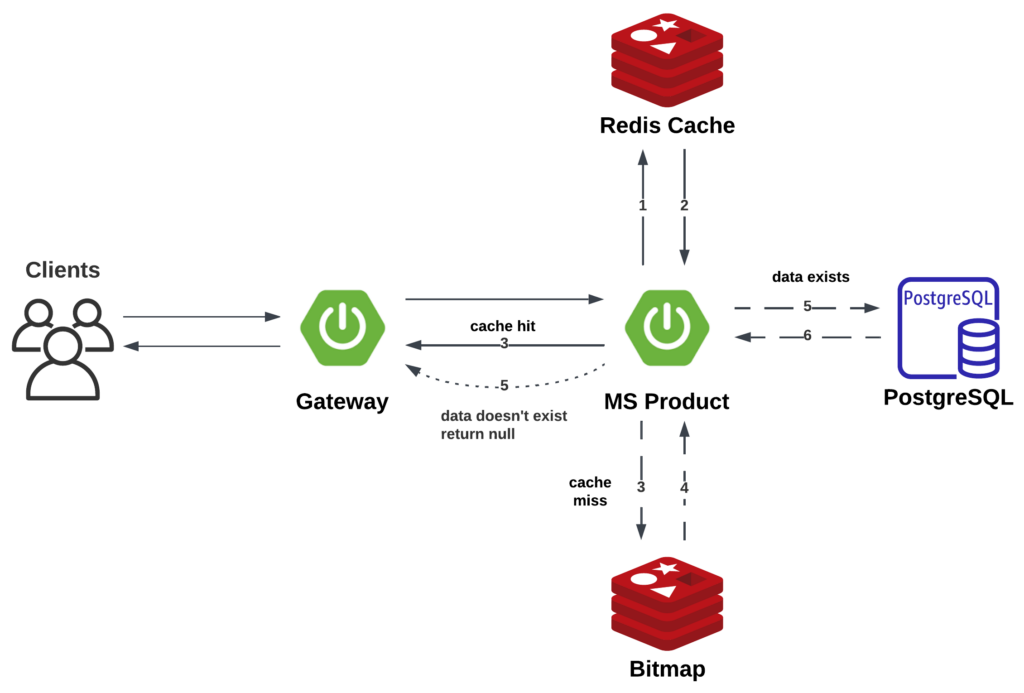
I used the bitmap functionality provided by Redis, using the data ID as the identifier.
If the bitmap indicates the data doesn’t exist, MS Product will throw an exception and flag the request as a potential attack.
Cache Breakdown
Cache breakdown occurs when the cache for a hot data expires, before a new cache can be added, a large number of requests will bypass the cache and putting pressure on the database.
To resolve this issue, we need to ensure that, in the same time, for the same data, only one request can reach to the database, while all other requests need to wait and retrieve that data from the cache.
Traditionally, we can use JUC (java.util.concurrent) to control the access to a data in multi-threaded/request environment. However, in a microservice application, this approach won’t work because requests are handled by multiple microservice instances, and JUC only manages locks within a single microservice instance. In this case, we need a distributed lock mechanism that operates outside the individual microservices, ensuring the lock is independent of any specific microservice instance.
I used the Redis Lock (RLock) with Redisson. The logic is as follows:
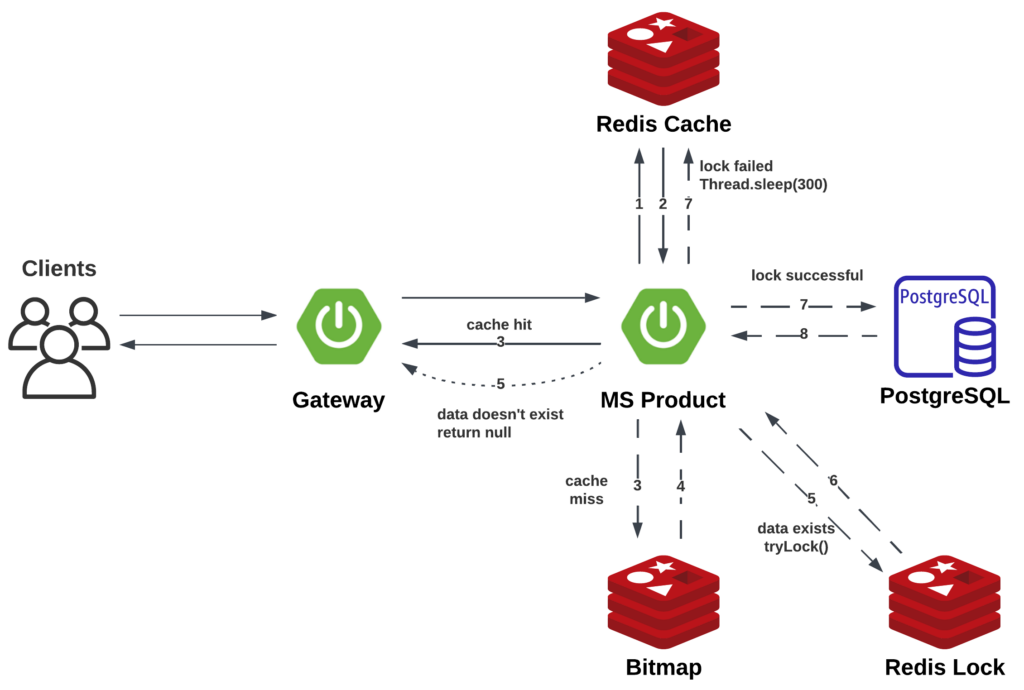
Pseudocode:
// get distributed lock from redisson
rLock = redissonClient.getLock(lockKey)
// try lock
locked = rLock.tryLock()
if (locked) {
// you have the lock
// query database
data = pjp.proceed()
// Save record into cache
cacheService.saveDataToCache(data)
// Return data
return data
} else {
// all other requests need to wait and query the cache
Thread.sleep(300)
return cacheService.getDataFromCache()
}Cache Avalanche
Cache avalanche occurs when a large number of caches expire at the same time, immediately after a lot of requests come in querying those data whose cache has just expired. This will add significant pressure to the database.
This scenario rarely happens, and it’s relatively easy to prevent. We can add a random TTL when saving caches. We can also load hot data into the cache before system startup or before a large-scale cache expiration.
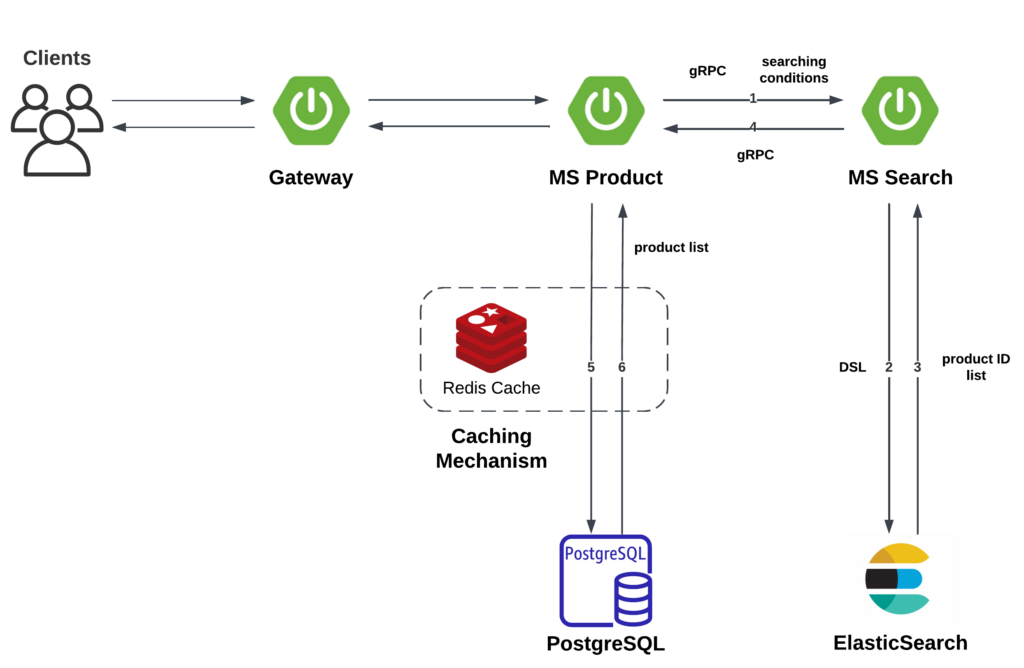
4. Searching
The search feature is powered by ElasticSearch. The data flow is shown below:
5. Authentication
Session-Based Token Auth
Thank you for reading, I’m still working on this document.